Infrastructure cost has a quiet way of growing until it is suddenly a board-level line item. In one advisory engagement, a crypto company's blockchain RPC spend had climbed to tens of thousands of dollars per month, far more than their actual on-chain activity justified. The dashboards showed the symptom, a large bill, but not the cause. This is the story of how that kind of waste hides, and how to find it.
What RPC spend is, and why it creeps
Applications talk to a blockchain through RPC (remote procedure call) endpoints: read a balance, fetch a block, check a contract's state. Each call is cheap. The trouble is volume. When call patterns are inefficient, cost scales with traffic, and nobody notices until growth turns a small leak into a flood.
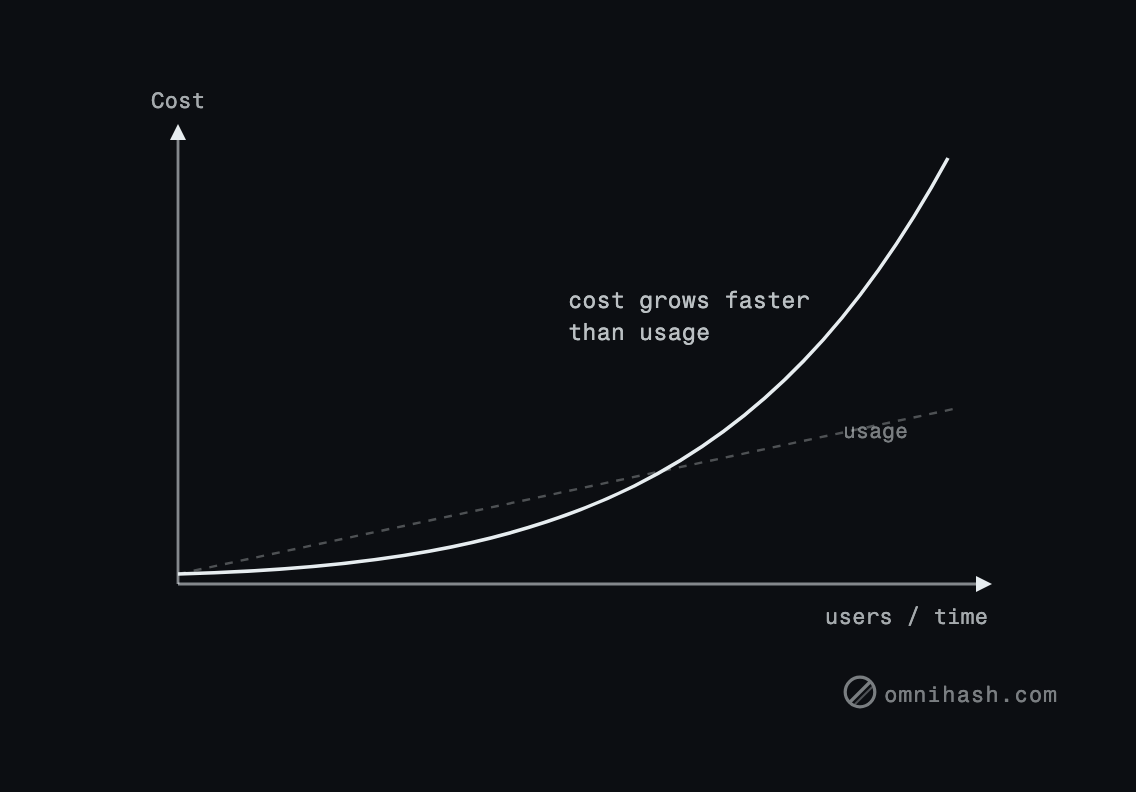 Figure 1. Inefficient per-action call patterns turn linear user growth into super-linear cost. The leak was always there; scale just made it visible.
Figure 1. Inefficient per-action call patterns turn linear user growth into super-linear cost. The leak was always there; scale just made it visible.
How we found it
The work was a straightforward audit, done in order:
- Measure first. Profile where calls originate and how many each user action triggers. You cannot fix what you have not counted.
- Trace the hot paths. A small number of code paths almost always drives most of the volume. Follow the frontend and contract interactions to the source.
- Find the redundancy. Look for the same data fetched repeatedly, calls made in render loops, missing caching, and requests that could be batched.
That trail led to a specific bug responsible for a large share of the wasted calls. Fixing it cut the recurring spend by tens of thousands of dollars per month, with no change to what the product did for users.
The usual suspects, in a table
| Pattern | What it looks like | The fix |
|---|---|---|
| Refetch in a loop | The same read on every render or tick | Cache and reuse, subscribe instead of poll |
| No batching | Many single calls that could be one | Batch or multicall |
| Over-polling | Frequent polling for rarely-changing data | Back off, or move to events |
| Duplicate reads | Several components fetch the same thing | Share a single cached source |
What you can check yourself
You do not need an outside audit to catch the obvious cases. Ask:
- How many RPC calls does one common user action trigger? Count them.
- Are you polling for data that changes rarely, or that you could subscribe to?
- Is the same value fetched by several components independently?
- Do your calls batch where the provider supports it?
Infrastructure waste is rarely one dramatic mistake. It is a small inefficiency multiplied by traffic. The fix is almost always measurement first, then caching, batching, and removing redundant reads.
The broader lesson
This was a crypto engagement, but the shape is universal. Costs that scale with usage hide their root cause behind growth. The way out is the same everywhere: instrument the spend, trace the hot paths, and attack redundancy before you attack the bill.
If your infrastructure cost is rising faster than your usage, that gap is usually a handful of fixable patterns. We are happy to help you find them.