The cheapest engineer on your team may be the most expensive person you employ. Not in what you pay them, but in what they spend on your behalf, and in what you get back for the total.
For most of the history of knowledge work, the cost of an employee was a stable two-part sum: salary plus benefits. Everything else was a rounding error. A laptop, a few SaaS seats, some cloud. Real, but small and flat, the same for your best engineer and your weakest one. That assumption is quietly breaking. When every engineer and analyst now runs AI tools and agents continuously, a third term has joined the equation, and unlike the others it varies enormously from person to person.
The new cost of an employee is salary plus benefits plus token spend.
 Figure 1. The cost of an employee in the AI era: salary plus benefits plus token spend.
Figure 1. The cost of an employee in the AI era: salary plus benefits plus token spend.
Here is the analogy we keep returning to. You would not pay a pilot trained on a Cessna to fly an F-35. The jet is far more capable, but capability in unpracticed hands is not output, it is burned fuel and bent metal. AI tooling is the F-35 of knowledge work: powerful, expensive to run, and unforgiving of poor judgment. Put someone who has only flown a Cessna in the cockpit and you do not get fighter-jet results, you get a very expensive crash. The price of the pilot was never the point. The point is what they do with the aircraft, and what it costs you when they fly it badly.
Token spend is a real line item now
Walk through what a working day looks like in a team that has gone all-in on agent-driven development. An engineer has an agent running in the editor, another in the terminal, a few model-backed tools for search and review, and a habit of asking a model before asking a colleague. Each of those calls is cheap. The pattern, repeated all day across a team, is not.
This is the same shape we wrote about in our crypto RPC cost audit: a per-action cost that is trivial in isolation and significant at volume. The difference is that RPC waste hid behind user growth. Token spend hides behind headcount, and it scales with how each individual works.
We are deliberately not going to attach hard numbers to this, because they would be invented and would date instantly. But the shape is easy to feel. Treat these as illustrative only: a disciplined engineer might run up a modest monthly token bill, call it a low hundreds of dollars. A heavy-but-effective one, several times that. And a genuinely wasteful operator, running agents in circles, can spend a multiple again, sometimes rivaling a meaningful fraction of a junior salary on a monthly basis. The point is not the figure. The point is that the spread between people is now wide enough to matter, and it tracks judgment, not job title.
How a low-judgment operator runs up the bill
Token waste is not about typing the wrong thing once. It is a set of habits, and they are the same habits that produce weak output. That is the whole argument: the waste and the weakness come from the same place.
- Re-running agents aimlessly. When the result is not right, the reflex is to run it again, and again, hoping for a better roll of the dice, instead of asking why it failed. Each spin costs tokens and produces nothing.
- Brute-forcing instead of reasoning. Handing the whole problem to the model and letting it grind, rather than thinking for thirty seconds about the right approach and giving it a smaller, sharper task. The model burns tokens exploring a space a moment of human reasoning would have pruned.
- No eval or test discipline. Without a way to check whether output is correct, every change is a guess, and guesses get re-run. We have argued before that you cannot ship a reliable AI feature without evals. The same lack of a measuring stick that ships bugs also burns tokens, because the only way to find out if something worked is to run it again.
- Regenerating instead of fixing. A small flaw in a large generated output gets fixed by regenerating the entire thing, repeatedly, instead of editing the ten lines that were wrong.
- Not knowing when to stop. The hardest one. A weak operator does not recognize a good-enough answer, or a dead end, and keeps spending past the point of return.
None of these is exotic. They are what it looks like when someone uses a powerful tool without the judgment to aim it.
How a strong engineer extracts more output per token
The same tools in stronger hands look completely different, and the savings are a byproduct of doing the work well.
- Better prompts and scoping. A precise, well-scoped request gets a usable answer on the first or second try, not the sixth. Most token waste is re-asking.
- Knowing when to use a model and when not. A strong engineer reaches for the agent on the boring sixty percent and thinks for themselves on the forty percent that needs it, which is exactly the split we described in our piece on agent-driven development. They also reach for the right size of model, not the largest one for every keystroke.
- Verifying instead of trusting. They have an eval set or at least tests, so they confirm an answer once and move on, rather than re-running to build confidence they should have gotten from a check.
- Knowing when to stop. They recognize a good answer, accept it, and close the loop. They also recognize a dead end early and change approach instead of feeding the same failing prompt more tokens.
The strong engineer is not being frugal. They are being effective, and lower spend falls out of it for free.
The metric is cost per unit of useful output
Once token spend varies this much, comparing hires on salary alone is measuring the wrong thing. The honest metric is total cost per unit of useful output: salary plus benefits plus token and tool spend, divided by what actually shipped and survived review.
Here is the comparison that matters, with illustrative figures only, chosen to show the shape rather than to assert real data.
| Cheap hire | Quality hire | |
|---|---|---|
| Salary | Lower | Higher |
| Benefits | Lower | Higher |
| Token and tool spend | High, much of it wasted on re-runs | Low to moderate, little waste |
| Useful output (merged, correct, kept) | Low | High |
| Effective cost per unit of useful output | Higher | Lower |
The salary line is the only one where the cheap hire wins, and it is the only line most hiring conversations look at. Add the token spend they run up, then divide by the small amount of work that actually clears the bar, and the cheap hire can cost more per shipped unit than the expensive one. You paid less for the person and more for the output.
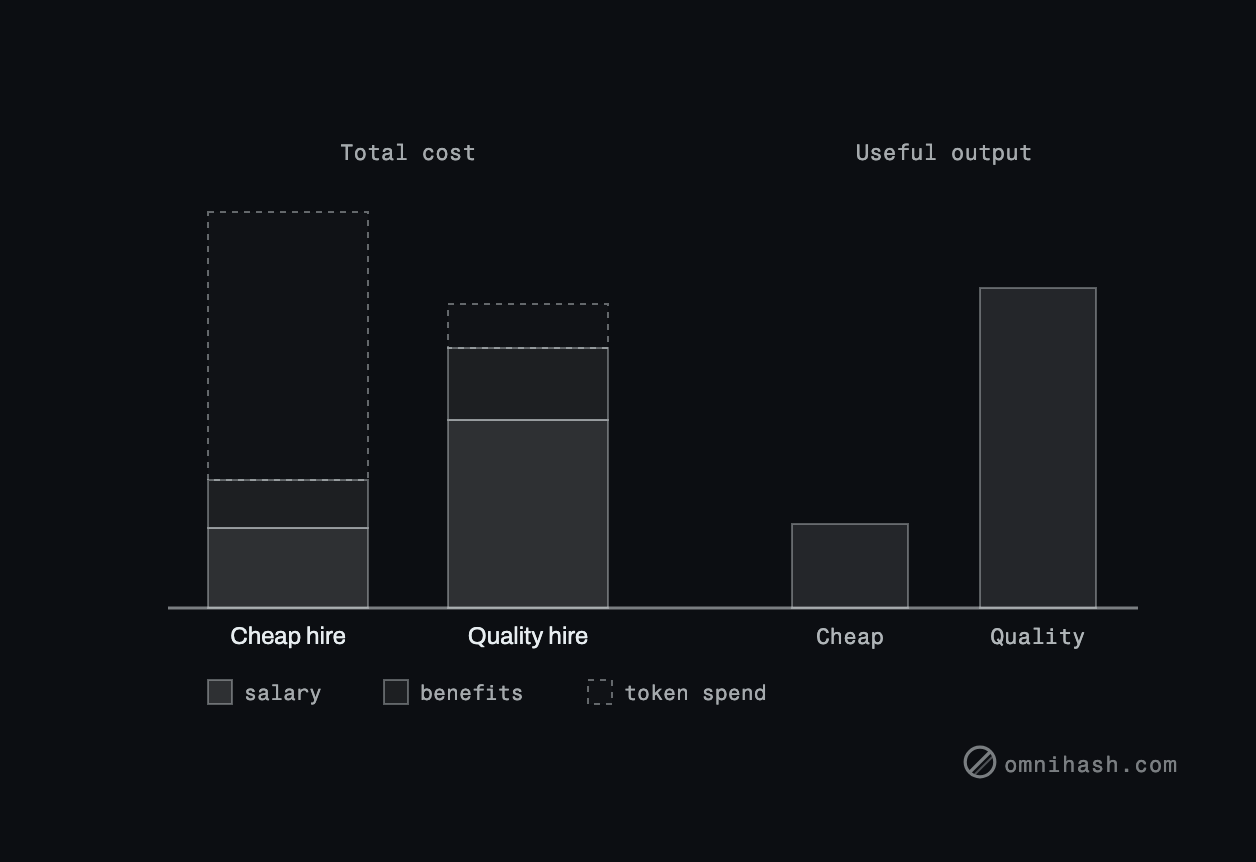 Figure 2. Two hires, total cost against useful output. The cheap hire has a lower salary but a large, mostly wasted token-spend segment and little useful output; the quality hire has a higher salary, a small efficient token-spend segment, and high output.
Figure 2. Two hires, total cost against useful output. The cheap hire has a lower salary but a large, mostly wasted token-spend segment and little useful output; the quality hire has a higher salary, a small efficient token-spend segment, and high output.
There is a second-order cost the table does not capture: someone has to review all that low-quality, high-volume output, and review does not get cheaper when generation gets faster. A wasteful hire taxes the time of the strong people around them, which is the most expensive resource you have.
The hiring implication
The conclusion is not new, but the AI era sharpens it: quality compounds, and underpaying can be the expensive choice.
When the tools were passive, a weaker hire was simply slower. Their downside was bounded by how much they could personally do in a day. Agents remove that bound. A weak operator with an agent can now spend real money producing work that someone else has to throw away, at a rate their predecessors could never have managed. The tooling amplifies whatever judgment is driving it, including the absence of judgment. A better aircraft does not turn a Cessna pilot into a fighter pilot. It only lets them burn more fuel on the way down.
That is why paying extra for genuine quality is more defensible now than it was five years ago, not less. The premium you pay a strong engineer buys you three things at once: more useful output, lower token spend per unit of it, and less review drag on everyone else. The cheap hire saves you on exactly one line of a three-line bill and loses you on the other two.
None of this is an argument for spending without limits, on salaries or on tokens. It is an argument for measuring the right thing. Look at cost per unit of useful output, instrument your token spend per person the way you would any other variable cost, and the picture usually clarifies fast.
At Omnihash we hire and build with quality-first talent precisely because we watch this math on our own work. The engineers who get the most out of these tools are the ones who needed the least supervision to begin with, and that is not a coincidence. If you are thinking about what good talent is actually worth in the AI era, the total-cost view is a useful place to start.