An engineer on a small team opens a spreadsheet. On one side, a recurring line item: a 200-dollar-per-month coding plan, times twelve, times however many people. On the other side, a single used graphics card and a quiet hum in the corner of the office. The question is not abstract. It is "do I buy a GPU and run models myself, or do I keep paying for Claude, Codex, and the APIs." This post is the honest version of that calculation, with real numbers as they stand at the time of writing in late June 2026. Prices move, especially GPU prices, so treat every figure here as a snapshot rather than a constant.
The hardware, and the one number that matters
The temptation is to shop for GPUs the way you shop for gaming cards, by raw speed. For local AI that is the wrong axis. The binding constraint is VRAM: how large a model, at what quantization, with how much context, fits on the card at all. A card that is twenty percent faster but cannot hold your model is not twenty percent better, it is useless for that model. Speed decides how fast tokens come out. VRAM decides whether they come out.
That single fact reorders the whole market. It is why a five-year-old card is still the value king.
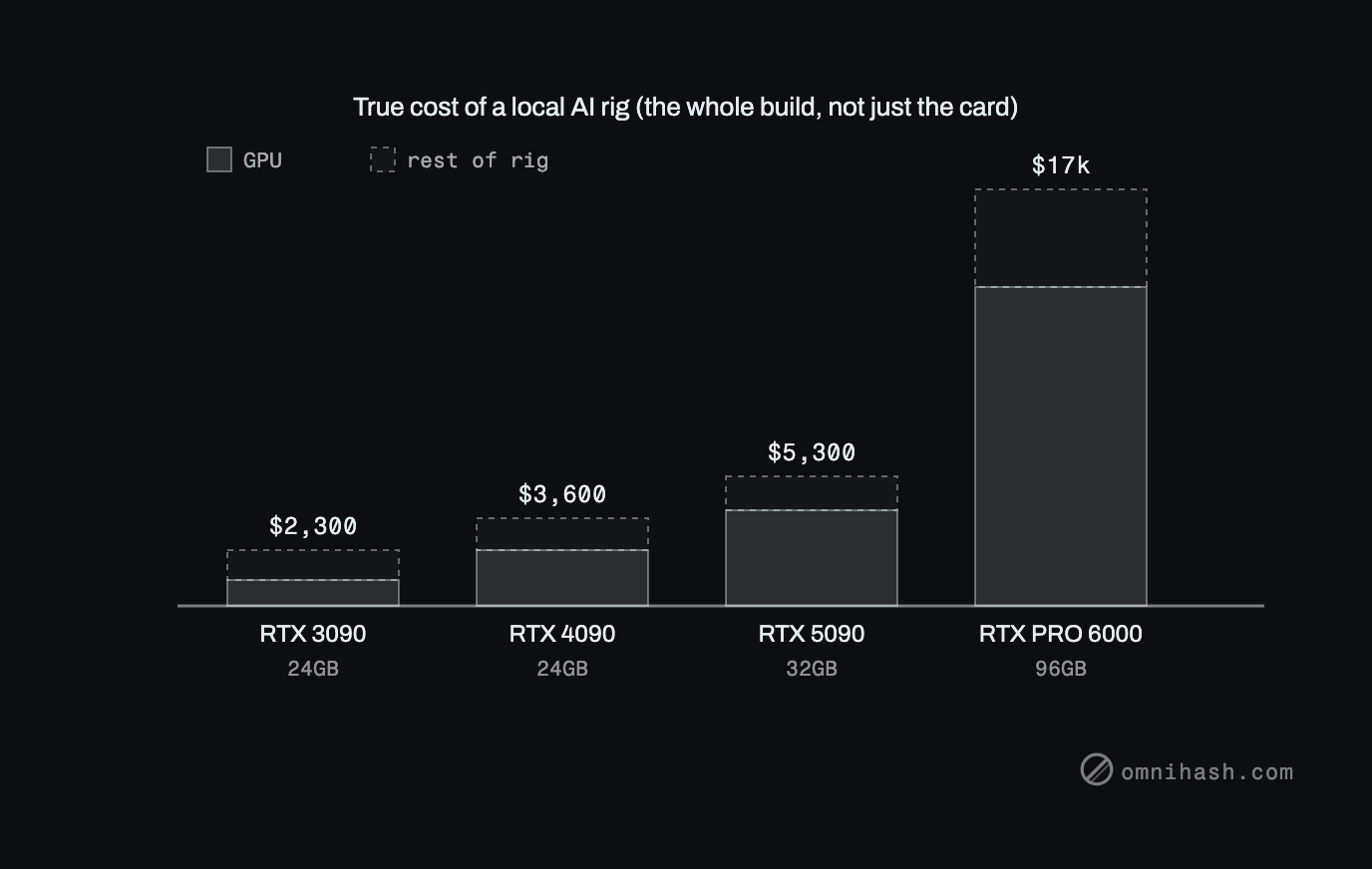 Figure 1. GPU street prices at the time of writing: a used 3090 near 1,100 dollars, a used 4090 near 2,300, a 5090 near 4,000, and the RTX PRO 6000 Blackwell well into the thousands.
Figure 1. GPU street prices at the time of writing: a used 3090 near 1,100 dollars, a used 4090 near 2,300, a 5090 near 4,000, and the RTX PRO 6000 Blackwell well into the thousands.
| Card | VRAM | Approx price (June 2026) | What it comfortably runs |
|---|---|---|---|
| Used RTX 3090 | 24GB GDDR6X, 936 GB/s | ~1,000 to 1,200 USD | 7B to ~32B open weights at good quantization |
| Used RTX 4090 | 24GB | ~2,300 USD | Same class as a 3090, faster |
| RTX 5090 | 32GB GDDR7 | ~3,700 used, ~4,300 new | Slightly larger models, more headroom |
| AMD Radeon AI Pro R9700 | 32GB | ~1,300 USD | Similar tier, but ROCm tooling lags CUDA |
| RTX PRO 6000 Blackwell | 96GB GDDR7 ECC, 1,792 GB/s | ~8,500 to 9,200 USD (listed as high as 13,250) | 70B at high quality, 120B-class MoE, long context |
The used RTX 3090 is the card most people should start with. Twenty-four gigabytes of VRAM for around 1,000 to 1,200 dollars is still the best ratio on the market, and in raw speed it sits roughly in RTX 5070 territory, which is plenty. Note the arithmetic that drives a lot of real decisions: two used 3090s cost about the same as a single used 4090, and give you 48GB across two cards instead of 24. For models that shard cleanly, two cheaper cards often beat one expensive one.
The AMD R9700 is genuinely attractive on paper: 32GB, more power efficient, around 1,300 dollars. The catch is software. AMD's ROCm stack is still behind NVIDIA's CUDA for AI tooling, and "behind" in practice means more time fighting your environment and fewer projects that just work. If your priority is shipping rather than tinkering, NVIDIA is still the safe pick. That is not a knock on the silicon, it is an honest read of the ecosystem.
At the top sits the RTX PRO 6000 Blackwell, the serious single-card option: 96GB of GDDR7 ECC, 24,064 CUDA cores, 1,792 GB/s of bandwidth, 600 watts. New it runs roughly 8,500 to 9,200 dollars, and NVIDIA's own store has at times listed it as high as 13,250 because of a GDDR7 memory shortage. That is real money, but it buys a class of work a 24GB card simply cannot do.
What each tier can actually run
Frame everything by VRAM and the picture stays durable even as specific model names churn.
- 24GB (a 3090): comfortably runs strong 7B to roughly 32B open-weight models at good quantization. The current families worth knowing are Qwen, Llama, Mistral, Gemma, and OpenAI's own open-weight gpt-oss-20b. A 70B model only fits with heavy quantization or by splitting across two cards. Large mixture-of-experts models like gpt-oss-120b can run with CPU offload, but slowly enough that it is a demo, not a workflow.
- 96GB (an RTX PRO 6000): runs a 70B model at high-quality quantization, a 120B-class MoE, long context windows, several models loaded at once, or real fine-tuning headroom. This is where local stops feeling like a compromise.
- Frontier-scale open weights (DeepSeek-class models at 600B-plus, Llama 4 Maverick-class 400B MoE) do not fit on one card at all. They need a multi-GPU rig or the cloud.
One caveat to keep front of mind, because it is the honest part: local open-weight models are excellent and improving fast, but they still trail the best closed frontier models (Claude, GPT and Codex) on the hardest coding and reasoning tasks. You are trading some capability at the top end for control and cost. Whether that trade is worth it depends entirely on what fraction of your work actually needs the top end.
The cost comparison, which is the whole point
Here is the structural difference that the spreadsheet is really about. A GPU is a one-time capital cost plus a little electricity. Claude and Codex subscriptions are recurring, every month, forever. Those two shapes cross at a break-even point, and where they cross depends on which plan you are comparing against.
A used 3090 at around 1,100 dollars breaks even against a 200-dollar-per-month plan in about five to six months. Against a 100-dollar plan, about eleven months. But against a 20-dollar-per-month entry plan, that same card stays more expensive than just paying the subscription for over four years. The entry tier is genuinely hard to beat on pure cost for light use.
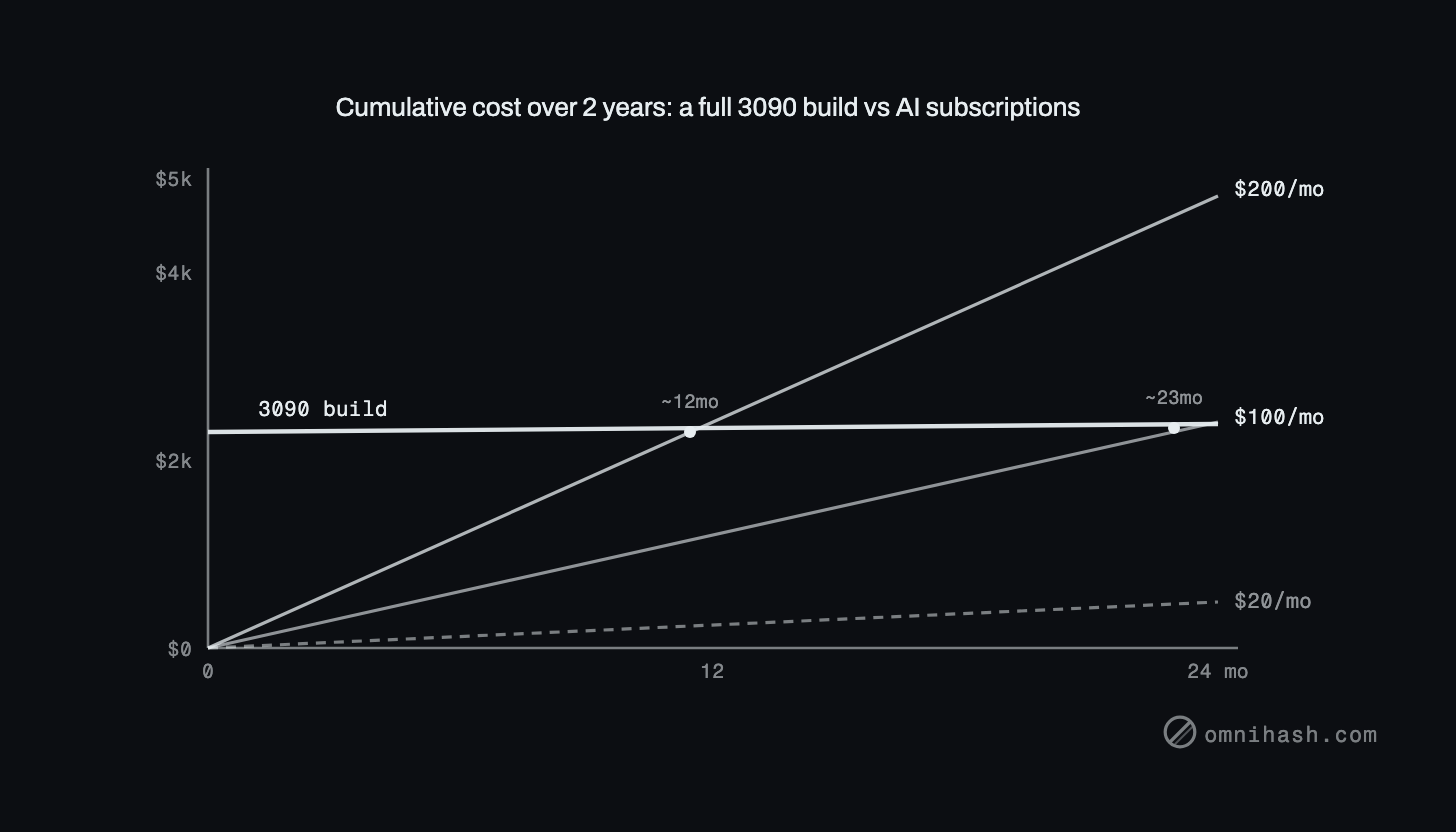 Figure 2. Cumulative cost over two years: a one-time used 3090 (around 1,100 dollars) as a flat line, against 20, 100, and 200 dollar-per-month plans as rising lines, with the break-even crossings marked at roughly six and eleven months.
Figure 2. Cumulative cost over two years: a one-time used 3090 (around 1,100 dollars) as a flat line, against 20, 100, and 200 dollar-per-month plans as rising lines, with the break-even crossings marked at roughly six and eleven months.
Electricity is the line everyone forgets, though it is small. A 3090 pulls around 350 watts under load, an RTX PRO 6000 around 600. At typical US power prices that is a few dollars to low tens of dollars per month even under heavy use. Real, but small next to the card. Do not let it swing the decision, just do not pretend it is zero.
Two more options round out the field. Cloud GPU rental lets you touch frontier-scale hardware without capital outlay: at the time of writing an H100 runs roughly 1.40 to 3.00 dollars per GPU-hour depending on provider, and an RTX PRO 6000 ranges from about 1.42 on Vast.ai to around 4.50 on Google Cloud. Frontier subscriptions and APIs sit on the other side: entry coding and chat plans (ChatGPT Plus, Claude Pro, Cursor Pro) around 20 dollars per month, heavy-use tiers (Claude Max, ChatGPT Pro, Codex usage) around 100 to 200, and raw API access billed per token, which can be a few dollars a month for light use or several hundred-plus for heavy agentic coding.
| Dimension | Local hardware | Frontier subscriptions / APIs |
|---|---|---|
| Upfront cost | High: ~1,100 USD and up, once | None |
| Ongoing cost | Just electricity, a few to tens of dollars/month | 20 to 200+ USD/month, or per-token forever |
| Capability ceiling | Strong open weights, trails the very best | The best models on the hardest tasks |
| Privacy | Full: data never leaves your machine | Data goes to a vendor under their terms |
| Ops burden | Yours: drivers, models, heat, noise, uptime | Zero: someone else runs it |
| Best for | Heavy, continuous, parallel, private work | The hard 20 percent, light or bursty use |
How to actually decide
The framing that holds up is not local versus cloud as a war to be won. It is a question of where each one fits.
Local wins for heavy and continuous use, for privacy and on-prem requirements, for fine-tuning, and for batch or embarrassingly-parallel workloads where you would otherwise be metering every token. It also wins on predictable cost at scale: a card you own does not send you a surprise bill when usage spikes. And GPUs hold their value, so the capital is not gone, it is parked. A 3090 you buy today can be resold.
Frontier subscriptions and APIs win for the hardest tasks, for zero operational burden, and for light or bursty use where a card would sit idle. The ops burden is the part people underestimate: running your own models means owning drivers, quantization choices, model updates, thermals, noise, and uptime. That is real work, and for a two-person team it competes directly with shipping.
So the honest answer, most of the time, is both. Run local for the bulk: the routine generation, the batch jobs, the privacy-sensitive work, the high-volume tasks where per-token pricing would bleed you. Reach for Claude or Codex for the hard 20 percent where the frontier still clearly wins. The two compose better than either does alone.
A last piece of practical advice: rent before you buy. Before committing 1,100 or 9,000 dollars to a card, spend a few dollars an hour on a cloud GPU and run your actual workload on it. You will learn your real VRAM needs and your real throughput in an afternoon, and you will size the purchase to evidence instead of a forum thread.
Privacy and control are not abstractions for us. A lot of the production work we do at Omnihash involves data that genuinely cannot leave a customer's boundary, and for that kind of build, local and on-prem inference is not a cost optimization, it is a requirement. If you are pricing out a setup like this for real work, we are happy to help you size it honestly, including the cases where the right answer is to just pay for the subscription.