A retrieval-augmented generation (RAG) demo takes an afternoon. A RAG system you would put in front of clinicians, analysts, or paying customers is a different animal. The gap between the two is where most projects stall, and it has almost nothing to do with which model you picked.
Here is what actually decides whether production RAG works.
The pipeline, and where it breaks
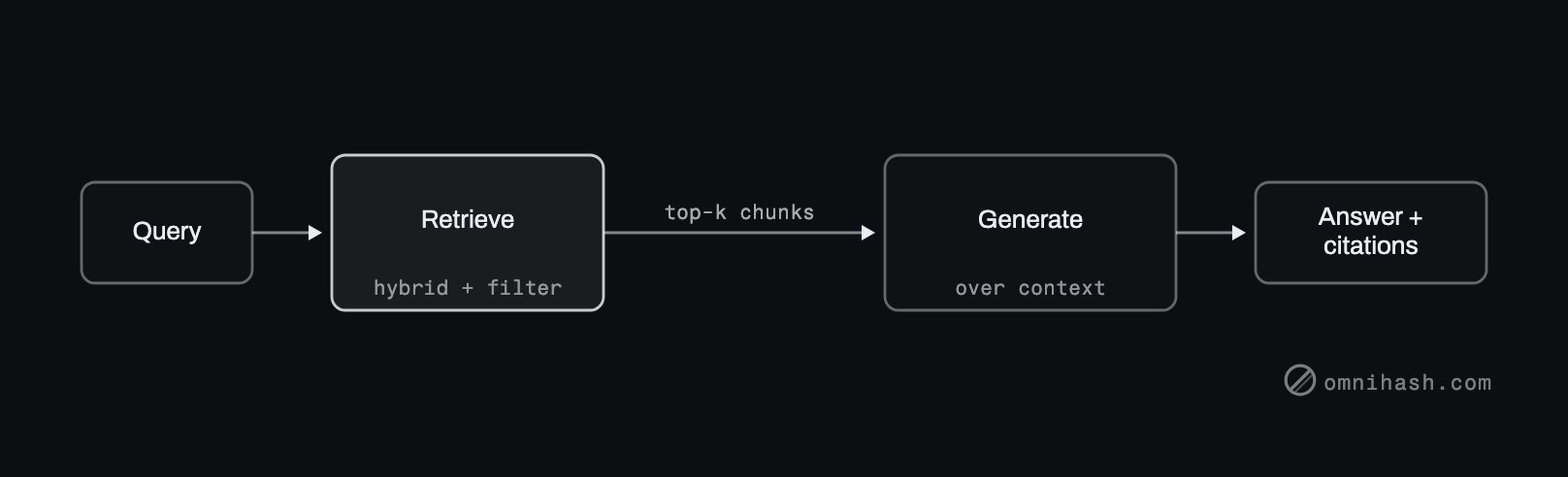 Figure 1. A RAG pipeline. The quality of the answer is capped by the quality of retrieval. Most teams over-invest in the last box and under-invest in the first.
Figure 1. A RAG pipeline. The quality of the answer is capped by the quality of retrieval. Most teams over-invest in the last box and under-invest in the first.
Retrieval quality beats model choice
The most common mistake is obsessing over the model while ignoring what you feed it. If retrieval surfaces the wrong context, the best model in the world will answer confidently from the wrong source. Spend your effort here:
- Chunk on meaning, not token counts. Split on structure (sections, clauses, records) so each chunk is self-contained and makes sense on its own.
- Use the right index for the query. Pure vector search misses exact matches like codes, identifiers, and names. Hybrid retrieval, keyword plus vector, almost always beats either alone.
- Filter with metadata. Constraining retrieval to the right scope (a tenant, a date range, a document type) often does more for accuracy than a bigger model.
You cannot improve what you do not measure
The single thing that separates production RAG from a demo is evaluation. Before tuning anything, build a small, honest eval set: real questions, known-good answers, and the sources that should be cited. Then a change is measurable instead of a vibe.
| Without evals | With evals |
|---|---|
| Every change is a guess | Every change has a number |
| Regressions ship silently | Regressions are caught before release |
| Debates about quality | Decisions about quality |
| Improvement by luck | Improvement by iteration |
Grounding and citations are not optional
If a user cannot see why the system said something, they will not trust it, and they are right not to. Ground every answer in retrieved source material and surface the citation. This does three jobs at once: it builds trust, it makes errors debuggable, and it gives you a natural guardrail. If nothing relevant was retrieved, the system should say so rather than improvise.
In one engagement we matched recommendations against the correct indications and tied every result back to its source, so a domain expert could verify the output at a glance. That verifiability was the product, not a nice-to-have.
Guardrails for the cases that matter
Decide in advance what the system does when it is unsure. "I do not have a confident answer from the sources" is a feature, especially when the stakes are real. Add checks for the failure modes specific to your domain rather than generic ones.
The constraints a demo never feels
- Latency. Users abandon slow answers. Cache, retrieve in parallel, and do not reach for a heavyweight model when a lighter one clears the bar.
- Cost. Token spend scales with usage in ways that surprise teams. Measure it per query early.
- Freshness. Source data changes. Have a real story for re-indexing, or your answers quietly go stale.
RAG is not hard because the concept is complex. It is hard because production is unforgiving about retrieval quality, evaluation, and trust. Get those three right and the model layer mostly takes care of itself.
If you have a RAG prototype that shines in the demo and stumbles in the wild, the gap is almost always one of the three above. We are happy to take a look.