"It looked good in testing" is the most expensive sentence in AI product work. It means someone typed a handful of prompts, liked what came back, and shipped. It is not a quality bar. It is a mood, recorded once, by the person least able to see the feature's blind spots. The reason you cannot ship a reliable AI feature on that basis is simple: an LLM does not fail loudly or consistently. It fails on the inputs you did not think to try, in ways that look fluent and confident, and you find out when a user does. The cure is not more careful manual poking. It is an evaluation set.
What an evaluation set actually is
An eval set is a fixed collection of real inputs paired with a way to judge the output. Nothing more exotic than that. Each case is two things: an input your system will actually see in production, and either a known-good output or a set of graded criteria the output must satisfy. The known-good output is the answer a competent human would accept. The graded criteria are the rules that matter when there is no single right answer: the response must cite a source, must not invent a price, must stay under a length, must refuse when the question is out of scope.
The point of writing this down is that it converts quality from something you feel into something you can run. Once the set exists, "is the feature good" stops being a debate and becomes a number.
How to build a small, honest one without boiling the ocean
The instinct to build a thousand-case golden set is how teams talk themselves out of building any. You do not need coverage of every input. You need an honest sample of the inputs that matter, including the ones that hurt.
- Start with twenty to fifty cases. A small set you actually maintain beats a large one you abandon. You can grow it later, and you will.
- Pull from real traffic, not your imagination. The inputs you invent are the inputs you already handle. Mine logs, support tickets, and early user sessions for the questions people actually ask.
- Include the failures on purpose. The cases that embarrassed you in a demo are the most valuable rows in the set. An eval set made only of happy paths is a comfort blanket, not a measurement.
- Write the criteria down before you grade. Decide what "correct" means for each case ahead of time, so you are scoring against a standard and not rationalizing whatever the model produced.
- Keep it honest. Do not quietly delete the cases your system fails. Those are the ones earning their place.
A set like this takes an afternoon to start. That afternoon is the difference between iterating and guessing.
Grading: three approaches, briefly
How you score a case depends on what the case is.
- Exact match. When there is one right answer (a classification label, an extracted field, a yes or no), compare strings. Cheap, deterministic, no ambiguity.
- Rules. When the output is freer but still has hard requirements, assert them: did it cite a source, did it stay in scope, did it avoid a forbidden claim, is it valid JSON. These catch the failures that matter most without needing a perfect reference answer.
- LLM as judge. When quality is genuinely subjective (tone, helpfulness, faithfulness to a source), use a model to grade against a rubric. It scales, but treat it with suspicion. A judge can be biased toward verbose answers, can drift as you change the grader, and can be wrong in correlated ways. Calibrate it against human judgment on a sample before you trust it, and never let it grade something a cheap rule could check instead.
Offline and online evals
There are two places to run evals, and you need both. Offline evals run against your fixed set before you ship, in your control, repeatable. Online evals sample real production traffic and grade it after the fact, which is the only way to see the inputs your fixed set never imagined.
| Dimension | Offline evals | Online evals |
|---|---|---|
| Runs against | Your fixed, curated set | Sampled live production traffic |
| When | Before you ship a change | Continuously, after release |
| Catches | Regressions you can reproduce | Drift and inputs you never anticipated |
| Speed | Seconds to minutes, repeatable | Ongoing, trailing |
| Main job | Gate the release | Watch reality and feed the set |
The loop between them is the point. Online evals surface a failing real input. That input becomes a new row in the offline set. The next change has to pass it. Your eval set gets smarter every week instead of staler.
How evals catch regressions
Here is where the discipline pays for itself. The three things you will change most often (the prompt, the model, the retrieval) are exactly the three that break silently. You tweak a prompt to fix one case and quietly degrade five others. You move to a cheaper or newer model and it is better on average and worse on the edge cases you care about. You change chunking or the index and retrieval quality shifts under you. None of this is visible by eye. All of it is visible against an eval set.
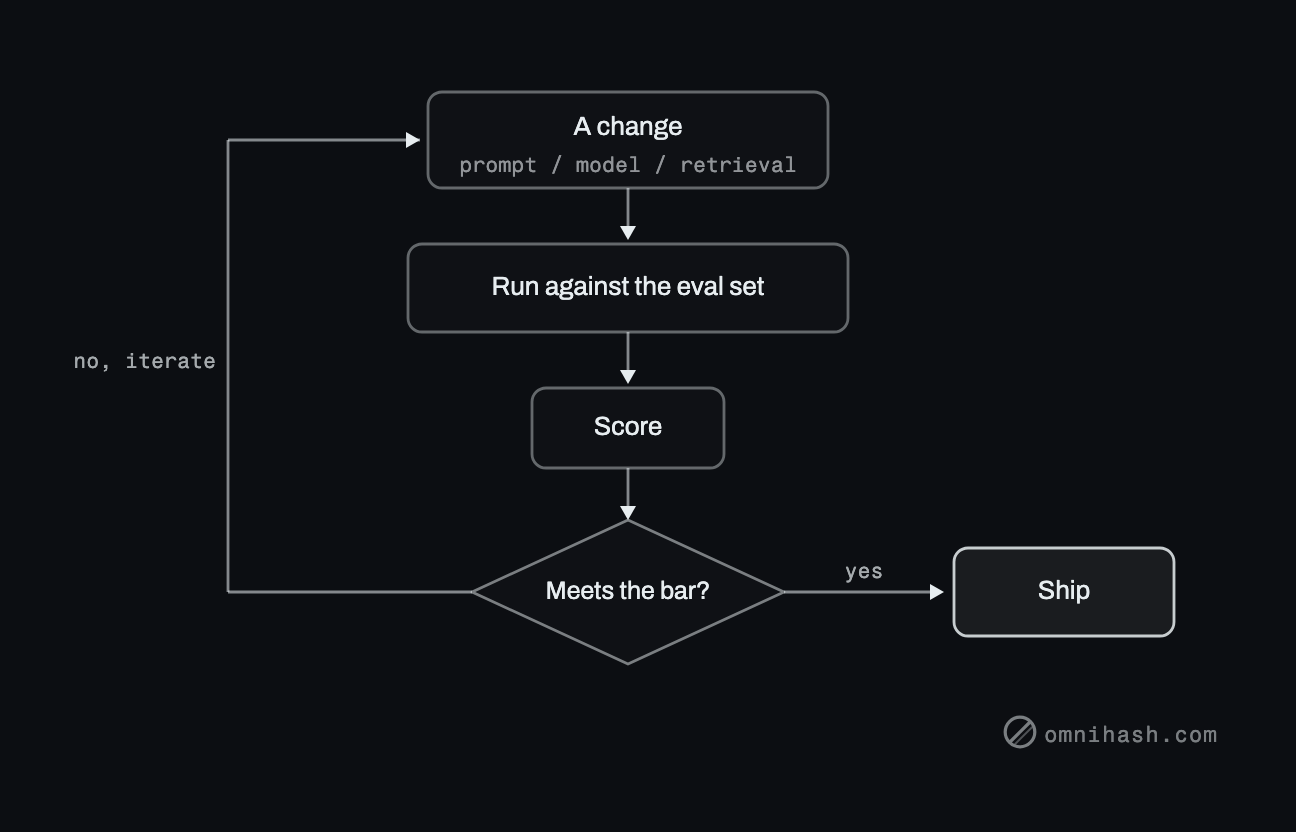 Figure 1. The eval gate. Any change runs against the eval set, produces a score, and meets a decision: clear the bar and ship, miss it and loop back to iterate.
Figure 1. The eval gate. Any change runs against the eval set, produces a score, and meets a decision: clear the bar and ship, miss it and loop back to iterate.
With the gate in place, every change is a measured experiment. You run the set, read the delta, and decide. A change that improves the average but breaks a critical case does not ship just because it felt better. This is the missing half of shipping RAG to production: retrieval quality is only knowable if you measure it.
Vibes versus measurement
The contrast is stark once you have lived on both sides.
| Shipping on vibes | Shipping on evals |
|---|---|
| "It looked good when I tried it" | "It scored 47 of 50, up from 44" |
| Regressions reach users first | Regressions caught before release |
| Prompt changes are arguments | Prompt changes are experiments |
| Model swaps are leaps of faith | Model swaps are measured deltas |
| Iterate by guessing, over days | Iterate by reading numbers, in hours |
That last row is the real prize. Without evals, every idea costs a day of manual testing and ends in a shrug. With them, you can try a prompt, a model, and a retrieval tweak before lunch, keep the one that scored best, and know why. Evals turn a quality argument into a measurement, and measurement is what lets you iterate in hours instead of guessing for a week.
The honest default
A reliable AI feature is not the one built by the smartest prompt. It is the one with a release gate that a change has to pass. Build the small set first, grade it honestly, run it before every change, and sample production to keep it grounded. Everything else in your stack gets easier once quality is a number you can see.
If you have an AI feature that shines in the demo and wobbles in the wild, the missing piece is almost always this one. At Omnihash we build evals into the work from the start, because it is the only way we know to ship AI we would stand behind. We are happy to take a look at yours.