Two techniques dominate the conversation when a team wants an LLM to "know" their domain: retrieval-augmented generation (RAG) and fine-tuning. They are not competitors. They solve different problems, and confusing the two is one of the most common and expensive mistakes we see.
This post is the decision guide we wish more teams had read before spending a quarter fine-tuning a model that needed RAG.
What each one actually does
RAG changes what the model knows at answer time. You retrieve relevant documents and put them in the prompt, so the model reasons over facts it can see right now. The knowledge lives in your data store, not in the weights.
Fine-tuning changes how the model behaves. You continue training on examples so the model adopts a format, a tone, a structure, or a narrow skill. The behavior lives in the weights.
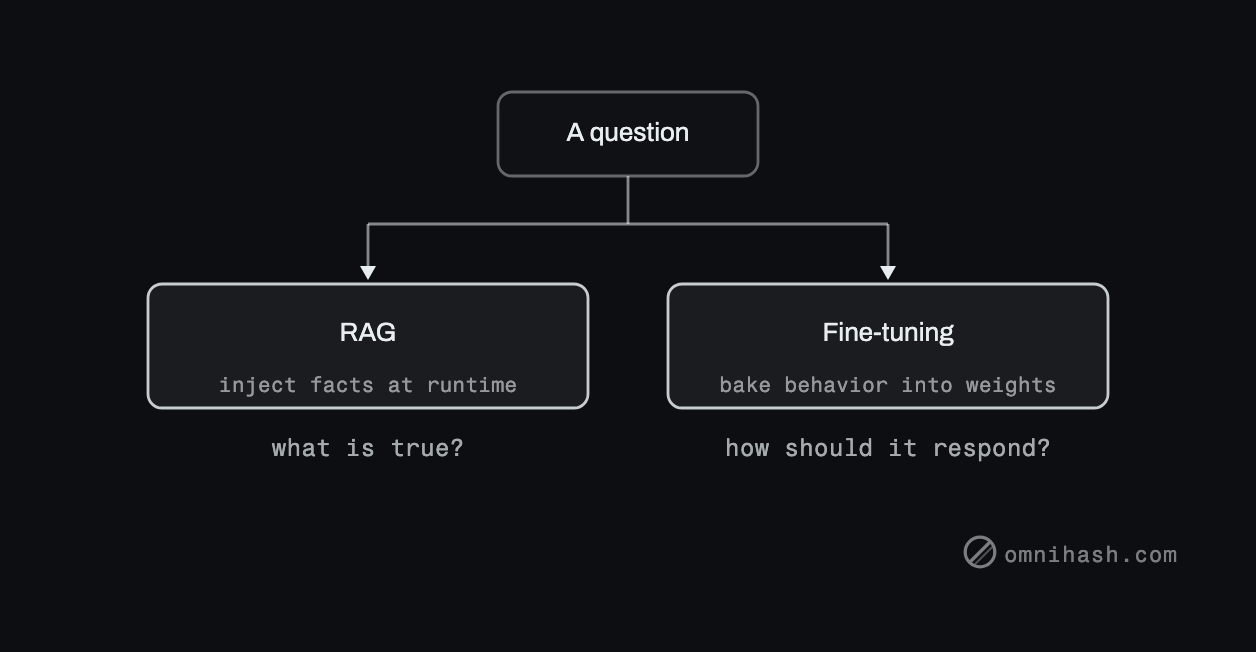 Figure 1. RAG supplies knowledge; fine-tuning shapes behavior. Most "the model does not know our stuff" problems are knowledge problems.
Figure 1. RAG supplies knowledge; fine-tuning shapes behavior. Most "the model does not know our stuff" problems are knowledge problems.
The rule of thumb
Reach for RAG when the problem is knowledge: the model needs facts it was not trained on, facts that change, or facts it must cite. Reach for fine-tuning when the problem is behavior: you need a consistent output shape or a specialized skill that prompting cannot reliably produce.
Most teams that say "the model does not know our business" have a knowledge problem. That is RAG, not fine-tuning.
A side-by-side comparison
| Dimension | RAG | Fine-tuning |
|---|---|---|
| Solves | Missing or changing knowledge | Inconsistent behavior or format |
| Freshness | Update the data, no retraining | Stale until you retrain |
| Citations | Natural, you retrieved the source | Hard, the model cannot cite weights |
| Upfront cost | Lower, mostly data plumbing | Higher, needs labeled examples and training |
| Iteration speed | Hours | Days per training run |
| Failure mode | Bad retrieval, wrong context | Overfitting, forgotten general skills |
When fine-tuning genuinely earns its place
Fine-tuning is not a trap, it is a tool with a narrower job. It is the right call when:
- You need a strict, repeatable output format and prompting keeps drifting.
- You have a high-volume, narrow task where a smaller fine-tuned model is cheaper and faster than a large general one.
- You need a tone or style that is hard to specify but easy to demonstrate with examples.
- Latency or cost targets push you toward a smaller model that needs help to match a larger one.
Even then, you usually fine-tune for behavior and still use RAG for knowledge. The two compose.
The decision flow
 Figure 2. Start with the cheapest thing that could work. Prompting and a good eval set solve more problems than either technique alone.
Figure 2. Start with the cheapest thing that could work. Prompting and a good eval set solve more problems than either technique alone.
Before you fine-tune anything, build an evaluation set. Without it you cannot tell whether fine-tuning helped, and you will spend training runs chasing a feeling instead of a number.
The honest default
For the large majority of "make the model understand our domain" projects, the right first move is strong prompting plus RAG, measured against a real eval set. Fine-tuning comes later, if and only if the data shows a behavior gap that retrieval cannot close.
If you are weighing the two for a specific product, we are happy to look at the actual requirement. The answer is usually clearer than the debate suggests.