Most RAG problems are chunking problems wearing a disguise. The retrieval misses, the confident answer from the wrong paragraph, the citation that points at half a sentence: teams blame the embedding model or the prompt, swap one of them, and the numbers barely move. The thing they skipped is the step that quietly decides everything downstream. You can only retrieve what you indexed, and you indexed chunks. If a chunk is garbage, no model recovers it.
This is the deep dive on the part of the pipeline almost everyone underinvests in. It complements shipping RAG to production, which argues retrieval quality beats model choice, and RAG vs fine-tuning, which argues most "the model does not know our stuff" problems are knowledge problems. Both are true. This post is about the lever underneath them.
Why chunking is the highest-leverage step
Retrieval quality is capped by chunk quality. Your retriever can only return units you created at index time. If the right fact lives split across two chunks, or buried in a chunk that is mostly about something else, even perfect retrieval hands the model a poor unit of context. Embeddings, rerankers, and hybrid search all operate on top of whatever you chunked. They cannot un-cut a sentence.
It is also the cheapest place to make progress. Re-chunking and re-indexing a corpus is hours of work. It does not need labeled data, a training run, or a model migration. Yet it sits at the very front of the pipeline, so a good decision there compounds through every query, forever. Highest leverage, lowest cost, and the box teams skip to go argue about which model to use.
The failure mode of naive fixed-size chunking
The default everyone starts with is "split every N tokens." It is one line of code and it is where the trouble begins. Counting tokens has no idea what a sentence is, let alone an idea. So the cut lands wherever the counter runs out: mid-sentence, mid-clause, mid-thought.
The damage is that the chunk is no longer self-contained. A fact gets separated from the context that makes it mean anything. "Refunds are issued within 30 days" ends up in one chunk and "if the item is unused" in the next. Retrieve either alone and you have a statement that is incomplete or, worse, misleading. The model answers from it confidently because it cannot see the seam.
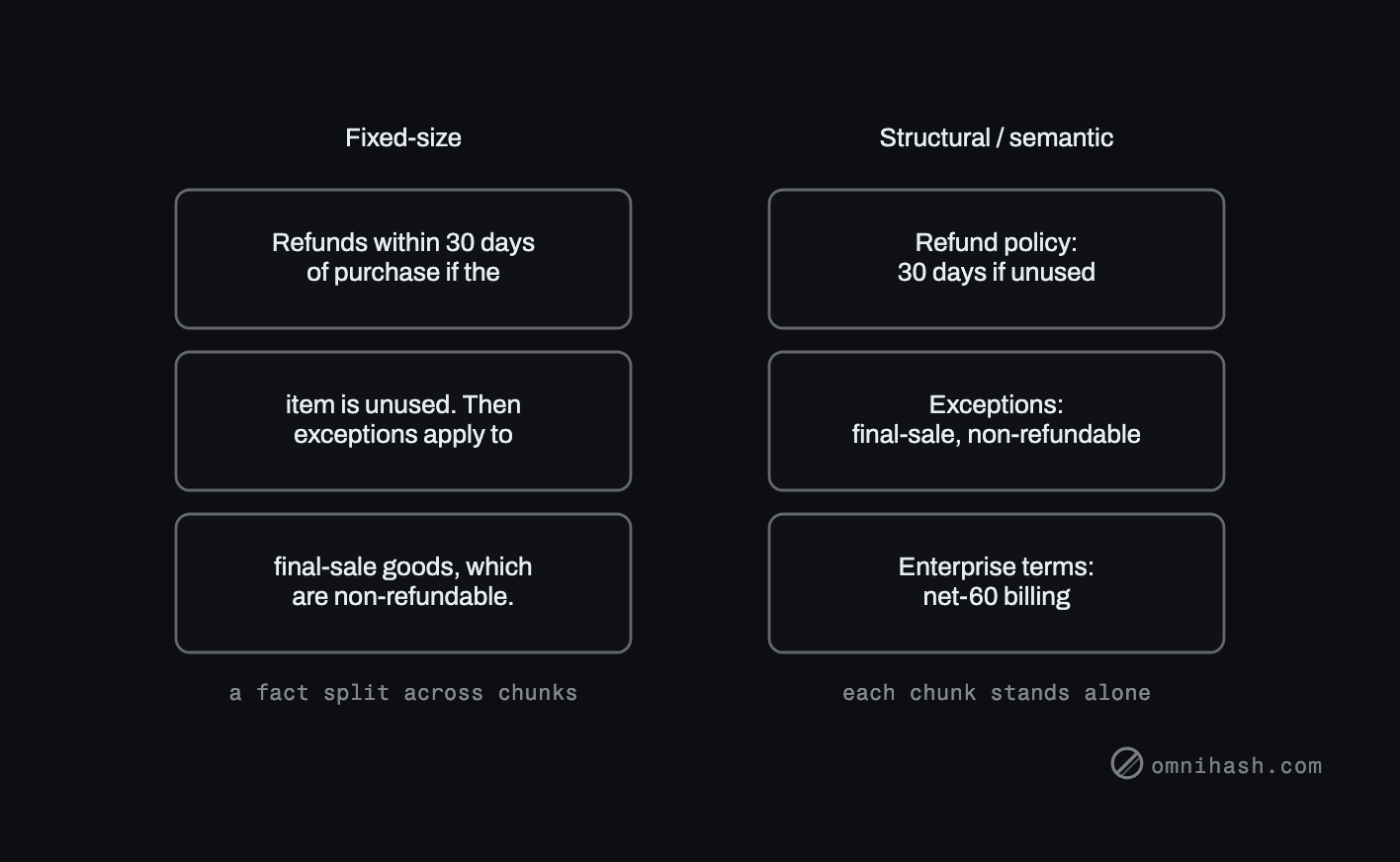 Figure 1. The same document, split two ways. Left: fixed-size cuts land mid-idea and strand a fact from its context. Right: structural and semantic cuts fall on natural boundaries, so each chunk stands on its own.
Figure 1. The same document, split two ways. Left: fixed-size cuts land mid-idea and strand a fact from its context. Right: structural and semantic cuts fall on natural boundaries, so each chunk stands on its own.
The fix is the same principle from the production post, stated more strongly here: chunk on meaning, not on token counts. The strategies below are increasingly disciplined ways to do that.
The strategies, and when each fits
Fixed-size with overlap. The cheap baseline. Split every N tokens, but slide a window so consecutive chunks share, say, 10 to 20 percent of their text. Overlap is a patch, not a cure: it raises the odds that a split fact appears whole somewhere, at the cost of duplicated tokens. Use it when documents have no usable structure (raw transcripts, OCR dumps) or as the honest starting point you will measure and then beat.
Recursive splitting on separators. Try to split on the biggest natural boundary first (double newlines for paragraphs), and only fall back to smaller ones (single newline, sentence, word) when a piece is still too large. This keeps paragraphs intact far more often than blind fixed-size, costs almost nothing more, and is the right default for prose without rich structure.
Structural chunking. Respect the document's own skeleton. Split on headings and sections, keep a list item or a table row whole, never cut a code block in half. The structure was put there by a human to group related ideas, so it is free, high-quality boundary information. This is the best default for anything with real structure: documentation, contracts, policies, knowledge bases, Markdown, HTML.
Semantic chunking. Walk the document sentence by sentence and start a new chunk where the topic shifts, detected by a drop in similarity between adjacent sentences. It produces beautifully coherent chunks and shines on long, flowing text with no headings (essays, interview notes, meeting transcripts). It costs more (you embed while you chunk) and it can be finicky to tune, so reach for it when structure is absent and coherence matters.
Parent-child (small-to-big). Decouple what you search from what you send. Index small, precise child chunks so retrieval is sharp, but when one hits, feed the model its larger parent (the full section or surrounding window) for context. You get the precision of small chunks and the completeness of large ones. This is our go-to for dense reference material where a query targets one line but the answer needs the paragraph around it.
| Strategy | Cost / complexity | Chunk coherence | Best for |
|---|---|---|---|
| Fixed-size + overlap | Lowest | Poor | Unstructured text, a baseline to beat |
| Recursive splitting | Low | Decent | General prose without rich structure |
| Structural | Low to medium | High | Docs, contracts, knowledge bases, Markdown |
| Semantic | Higher | High | Long flowing text with no headings |
| Parent-child | Medium | High (as served) | Dense reference where one line needs its section |
Size and overlap: the tradeoff nobody tunes
Chunk size is a dial with a cost at both ends. Too small and the chunk loses the context that makes it usable: a clause with no subject, a value with no label. Too large and you dilute relevance (one query-relevant sentence buried in a wall of unrelated text scores worse and retrieves worse) and you waste tokens shipping noise to the model on every call.
There is no universal number. Coherent units beat round numbers, which is exactly why structural and semantic splitting outperform: they let the content decide the size. Overlap follows the same logic. A little protects against boundary cuts; a lot is just paying twice to store the same words. Pick a starting point from your document type, then let the eval set move it.
Attach metadata, and handle the special cases
A chunk is not just text. Tag each one with where it came from: source, section, document type, date, tenant, version. Metadata lets you filter before you rank, and as the production post notes, constraining retrieval to the right scope often does more for accuracy than a bigger model. It also powers citations, which are how users come to trust the answer at all.
Some content refuses to behave as prose, and forcing it through a text splitter destroys it:
- Tables. Splitting by token count severs a cell from its column header and its row label, so the number means nothing. Keep rows whole and carry the header into each chunk, or serialize each row into a sentence that names its columns.
- Code. Cut a function in the middle and both halves are useless. Split on function and class boundaries, keep imports and signatures with the body.
- Structured records. A product, a patient, a transaction: chunk per record, not per token, so one retrieved unit is one complete entity.
Choose by document type, then measure
There is no winning strategy in the abstract. There is a strategy that fits your documents. So start from what you actually have: structured docs lean structural, flowing text leans semantic, reference material leans parent-child, and the unstructured leftovers get recursive or fixed-size with overlap. Most real corpora are a mix, and the honest answer is to chunk different document types differently.
Then refuse to guess. Chunking is exactly the kind of change that shifts retrieval quality silently, the kind an eval set exists to catch. Build the small, honest eval set the other posts insist on, with real questions and the sources that should be cited, and run each chunking choice against it. The right size, the right overlap, the right strategy per document type: these are numbers you measure, not opinions you hold. Tie every chunking decision to that measurement, or you are tuning by feel.
We spend a lot of time on this unglamorous layer because it is where retrieval is won or lost. If your RAG system retrieves the wrong thing more often than you would like, the chunks are the first place we would look, and we are happy to take a look with you.