Somewhere in every large company is a graveyard of AI pilots. Each one had a moment of glory: a meeting where the demo did exactly what it promised, the room leaned in, and someone said the word transformative. Then nothing shipped. The demo got a slot in a quarterly review, maybe a slide, and quietly stopped being mentioned. Six months later nobody can find the repository, and the budget moved to the next pilot that will die the same way.
This is not rare. It is the median outcome. And the reason is almost never the model. The models are good enough. Pilots die at the gap between an impressive demo and a thing in production, and that gap is made of work the demo was specifically designed to skip.
The gap is not a model problem
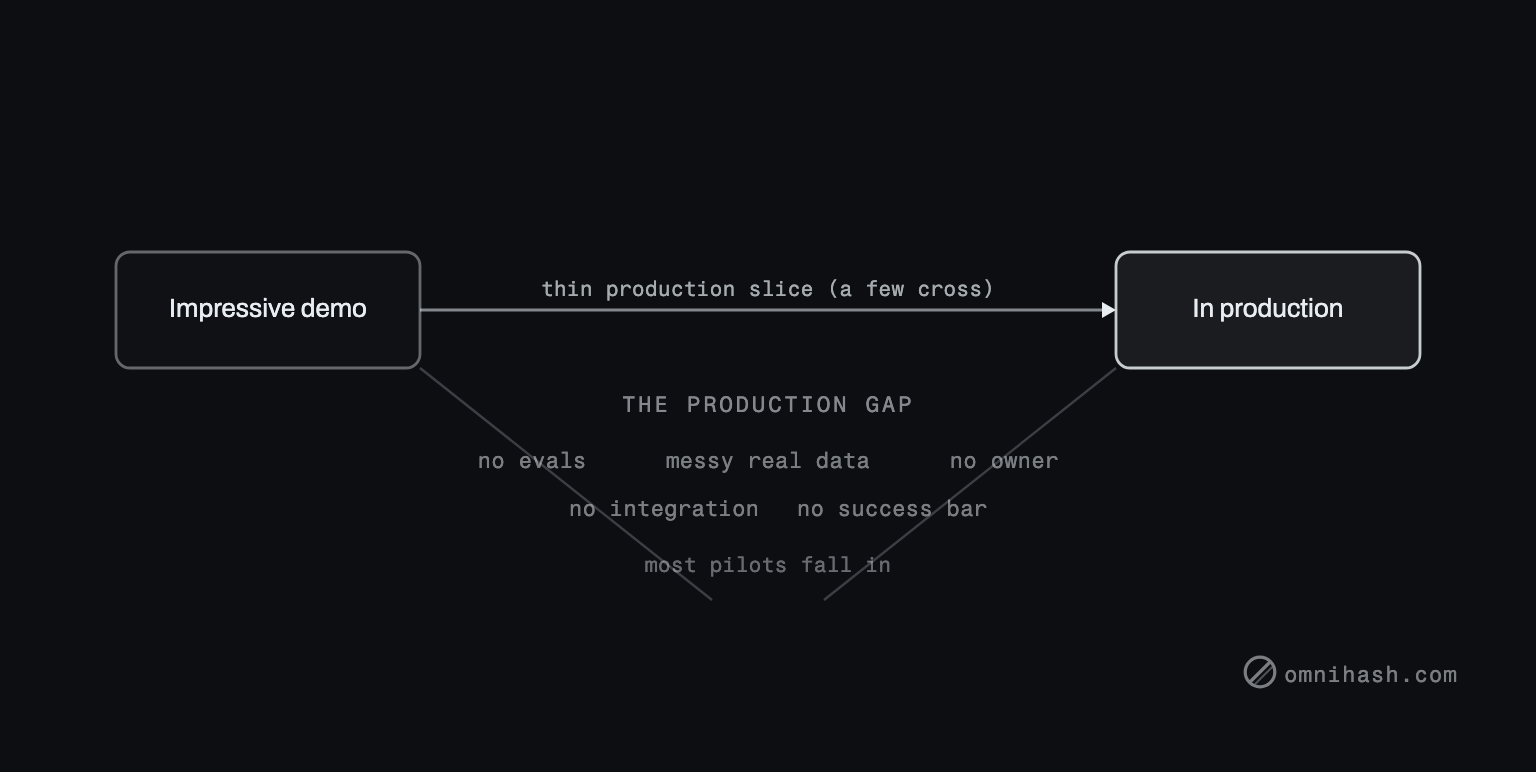 Figure 1. The demo-to-production gap. Most pilots reach an impressive demo, then fall into the gap that separates it from production. A thin bridge, scoping the pilot as a production slice, is the only thing that crosses.
Figure 1. The demo-to-production gap. Most pilots reach an impressive demo, then fall into the gap that separates it from production. A thin bridge, scoping the pilot as a production slice, is the only thing that crosses.
A demo is a performance. It is tuned, on purpose, to look its best in front of an audience that wants to be impressed. Production is the opposite: an unforgiving environment full of inputs nobody chose, data nobody cleaned, and users who do not care how clever the architecture is. The demo optimizes for the wow. Production optimizes for the worst case. Those are different artifacts, and treating the first as a draft of the second is the original sin of most pilots.
Here is the uncomfortable part. The things that make a demo fast to build are exactly the things that make it impossible to ship. Every shortcut that earned the applause is a debt that comes due at the production gate.
The specific reasons pilots stall
The demo had no evaluation set. It was tuned on a handful of happy-path inputs, the ones the builder tried, liked, and kept. That is not a quality bar, it is a mood recorded once. When someone finally asks "is this good enough to trust with real customers," nobody can answer, because nobody can measure it. Without an eval set, the pilot cannot prove it clears any bar, so the cautious and correct decision is to not ship it. The demo dies of its own unprovability.
The data was clean because someone cleaned it. The demo ran on a curated slice: a few hundred tidy records, hand-picked, deduplicated, well-formed. Production data is messy, siloed, access-controlled, and stored in three systems that disagree with each other. The moment the pilot meets real data, the accuracy that looked like ninety-five percent reveals itself as the accuracy of a fixture, not a feature. Connecting to the real source is not a finishing touch. It is most of the actual work, and it was never started.
There was no owner. The pilot was a side project for an innovation team, a sandbox group, or one motivated engineer between sprints. That works fine for building a demo and not at all for running a product. There is no on-call rotation, no team that will maintain it, no line in anyone's roadmap. When the question becomes "who runs this in production," the honest answer is nobody, and a thing nobody owns does not ship. It cannot.
Integration was never scoped. The demo skipped authentication, skipped the existing product surface, skipped the legacy API it would have to talk to, skipped permissions and audit and rate limits. It called a model and rendered a result. Wiring that into a running business (real auth, real systems, the boundary you actually own) is the bulk of the effort, and because the demo never touched it, nobody estimated it, and now it looks like a surprise instead of the plan. We make this same point about adding AI to an existing product: the model is the easy part, the integration is the work.
Nobody defined success. No one wrote down what the pilot had to achieve to graduate. Beat the current process by how much? Clear what accuracy on which inputs? Save how many minutes per task? Without a bar, "good enough" is a matter of taste, and taste does not survive a budget review. A pilot with no definition of done is a pilot that can never be done.
The whole thing was framed as a science experiment. This is the root cause under the other five. The organization treated the pilot as research, a question to explore, rather than as the smallest version of a real product. Experiments are allowed to end inconclusively. Products are not. Frame it as an experiment and you have given everyone permission to walk away the moment the novelty fades, which is precisely what happens.
What the demo had versus what production needs
| Dimension | What the demo had | What production needs |
|---|---|---|
| Data | A clean, curated, hand-picked sample | Messy, siloed, access-controlled real data |
| Evals | A few happy-path inputs the builder liked | A real eval set that proves it clears a bar |
| Integration | A standalone screen calling a model | Auth, existing systems, your own service boundary |
| Ownership | A side project, no on-call, no roadmap | A team that runs it and is accountable for it |
| Success criteria | "It looked impressive" | A written bar it must beat to graduate |
| Framing | A science experiment, allowed to fizzle | The smallest shippable version of a product |
Read that table as a list of the work that got deferred. None of it is exotic. All of it is the difference between a demo and a product, and all of it is cheaper to plan before the demo than to retrofit after it.
The antidote: scope the pilot as a thin production slice
The fix is not to make demos fancier. It is to stop building demos and start building the smallest real thing. A pilot should be a thin vertical slice that goes all the way to production from day one, narrow but complete, rather than wide but fake. Concretely:
- Define the success bar before you build. Write down the number the pilot must beat and the inputs it must beat it on. If you cannot state that, you are not ready to start, and finding that out now is the cheapest discovery you will make.
- Build the eval set first, not last. Twenty to fifty real cases, including the ones that hurt, with the criteria written down. Now every change is a measured experiment and "is it good enough" is a number, not an argument.
- Use real data early. Connect to a real slice of the actual, messy, access-controlled source. The accuracy that matters is accuracy on production data, and the sooner you meet it the sooner your estimate becomes honest.
- Scope integration and ownership before the demo, not after. Decide which team will run it and how it plugs into auth and your existing systems before you write the impressive part. If no team will own it, you do not have a pilot, you have a hobby.
- Pick a use case where a wrong answer is cheap. Drafting, summarizing, classifying, triage: places a human stays in the loop and an error costs a correction, not a catastrophe. Let trust, earned by evidence, move you toward higher stakes later.
None of this makes the first version more impressive. It makes it real, which is the only property that survives contact with production.
The smallest shippable thing beats the most impressive demo
This is the same scope-first argument we make about what an AI MVP actually costs, pointed at pilots. The teams that go over budget are not under-funded, they are over-scoped, and the teams whose pilots die are not under-talented, they built the wrong artifact. An impressive demo answers the question "could this look good." A thin production slice answers the question that actually matters: "will this work for real users, and can we prove it." Only one of those questions is worth money.
So the contrarian advice is simple. Stop trying to wow the room. The demo that gets the loudest applause is often the one most likely to die, because applause is what you get for skipping the hard parts. Build the smaller, less glamorous thing that has an eval set, real data, an owner, and a path into production, and ship that. It will impress fewer people in the meeting and far more people in production.
At Omnihash we build AI products that reach production rather than slide decks that describe them, and a good part of the job is helping teams scope the pilot as the smallest real version instead of the most impressive fake one. If you have a demo that dazzled and then stalled, the gap is almost always one of the six above. We are happy to take a look.